0. Introduction : de l’autocorrélation à la pauvreté
Les avancées économiques et sociales recomposent le paysage humain des pays asiatiques et l'Inde fournit un exemple remarquable de la rapidité et de l'ampleur des transformations en cours. Mais que l'on adopte le point de vue d'un sociologue, d'un économiste ou d'un démographe, la dimension géographique de ces dynamiques contemporaines reste essentielle pour comprendre leur nature, car le changement social et économique repose en grande partie sur des réseaux d'échange et de communication qui sont spatialement autant que socialement structurés. Les traces spatiales des mutations de la société sont particulièrement visibles en Inde du Sud, région du pays qui a enregistré en plusieurs domaines les changements les plus rapides: baisse de la fécondité, augmentation de l'agriculture irriguée, mais aussi accroissement de la discrimination sexuelle.
Le projet EMIS (Espace et Mesure en Inde du Sud) rassemble sept chercheurs de diverses disciplines réunis pour réaliser une analyse comparative de la structuration spatiale de l'Inde du Sud à partir d'un corpus d'informations unique, issu du recensement national, disponible sous forme de SIG. Ce projet explore à la fois des questions théoriques, sur la nature des structurations spatiales mesurées, mais également thématiques, liant les facteurs étudiés à leur mode de propagation locale ou régionale. L'analyse des informations disponibles a conduit dans un premier lieu à des examens des profils cartographiques de variables essentielles, dont les principaux résultats ont été rassemblés dans un atlas (Oliveau 2003). Elle se prolonge par une analyse multiscalaire, rendue possible par une agrégation à géométrie variable, de l'autocorrélation spatiale. Cette analyse mesure la forme des compacités observées, en faisant varier les indicateurs, les échelles, les unités spatiales et les régions de référence.
Le projet procède de trois développements dans le champ scientifique:
A. La disponibilité de données fines, désagrégées et pouvant être géoréférencées
L'analyse spatiale du changement social dans les pays en développement est un domaine fort peu exploré, en particulier parce qu'elle requiert des matériaux, notamment géostatistiques, qui font défaut dans la plupart de ces pays. Notre projet prend appui précisément sur l'existence d'une base de données spatialisée unique pour l'Inde décrivant les principales caractéristiques du développement social et économique: structure de l'emploi, discrimination de genre, natalité, développement de l’irrigation, développement des équipements ruraux.
B. L'intérêt pour la dimension spatiale du changement social à différentes échelles
La dimension spatiale est un thème crucial pour la compréhension générale des dynamiques du changement social et économique, dont le caractère déséquilibré à macro-échelle, et segmenté à micro échelle, est manifeste. La rapidité des transformations en Inde dans les domaines concernés (baisse de la fécondité, développement de l'irrigation, progrès de l'éducation, renforcement des infrastructures collectives, etc.) est remarquable, notamment en regard de l'inertie relative qui caractérise la géographie des pays riches ou de certains pays moins avancés. Cette évolution accélérée s'accompagne d'une trace spatiale, évidente à tous les niveaux de l'analyse, en dépit des efforts gouvernementaux pour redistribuer les fruits de la croissance et corriger les déséquilibres socio-spatiaux.
C. Le développement d'outils de traitement géostatistique applicables à des corpus de données sociales
L'analyse de la géographie du changement social relève habituellement de l'interprétation cartographique de la distribution des phénomènes à macro-échelle. Ces analyses n'intègrent pas les informations à un niveau plus fin (micro-régional ou local), faute de données ou de moyens de traitement. De plus, elles reposent sur des interprétations cartographiques globales qui privilégient l'intuition (visuelle notamment) sur l'analyse systématique du corpus des données.
Quelques mots enfin pour décrire le présent rapport, car la progression du travail de l’équipe a connu un développement inattendu, autour d’une problématique qui n’a émergé que lors de notre seconde phase de recherche. Le projet EMIS se fondait en effet à l’origine sur un protocole d'analyse systématique d'un ensemble de données pour la mesure et l'analyse approfondie de l'autocorrélation spatiale. On considérait ainsi que la distance offrait le meilleur indicateur indirect (proxy) de la densité des interactions entre groupes sociaux et localités, et permettait d'évaluer la nature et le rôle spécifique de la structuration spatiale en Inde du Sud dans les mécanismes de développement sociaux et économiques. Ces aspects de l’analyse spatiale classique sont présentés dans les premières parties de ce rapport, notamment la troisième partie qui est une étude de la structuration spatiale.
Au cours du projet, qui s’est organisé autour de réunions d’équipes régulières (sessions souvent normandes de brain storming en fin de semaine), les participants ont toutefois souhaité mettre en avant des thématiques plus concrètes et conférer ainsi plus de contenu à une démarche formelle jugée parfois bien aride. C’est ainsi que l’intérêt porté aux questions de spatialisation de la pauvreté a fait émerger des complémentarités thématiques originales entre géographes et autres praticiens des sciences sociales, autour d’une question spécifique (poverty mapping) qui intéresse avant tout les économistes du développement. La dernière partie du rapport est par conséquent consacrée à l’approche géographique de la vulnérabilité en Inde du sud et représente un segment distinct de notre trajectoire de recherche. Elle passe en revue certaines dimensions majeures de la vulnérabilité des populations, avec un accent particulier sur le monde rural et la géographie de l’irrigation qui ont fait l’objet d’un travail approfondi. Cette recherche offre, grâce aux instruments de modélisation spatiale que l’équipe s’est appropriés, une synthèse efficace sur les contours de la vulnérabilité en Inde du sud et représente d’ailleurs, par son échelle locale d’analyse, un apport tout à fait original dans le champ de la recherche sur l’Inde.
1. Etudier la spatialité socio-économique en Inde du sud
Que ce soit en Afrique, en Asie ou en Amérique du Sud, des croissances (économiques et démographiques) très différenciées ont lieu entraînant des divergences importantes au sein du monde en développement. Ces grands ensembles sont loin d’être homogènes, et les différents pays qui les composent connaissent aussi des fragmentations internes (entre régions, au sein des régions). Les inégalités sociales et économiques internes se structurent autour de différents groupes sociaux (ethnies, tribus, castes, etc.) mais ont aussi une géographie particulière. On opposera volontiers les « régions qui gagnent » (Benko et al., 2000 faisaient référence aux districts industriels Marshalliens) aux « trappes spatiales » de pauvreté. Les relations entre villes et campagnes restent quant à elle un terme majeur de compréhension des inégalités spatiales (Chaléard et al., 1999).
Au sein des sciences sociales, l’approche géographique se caractérise par un accent mis sur ce dernier point. Les dimensions spatiales et les jeux d’échelles des phénomènes étudiés sont la porte d’entrée privilégiée (mais non unique) de la géographie du développement. On cherche alors à décrire les formes observées, pour comprendre l’émergence, la permanence, voire la disparition des phénomènes examinés.
A l’échelle de l’Inde du Sud, le travail entrepris vise à comprendre la distribution et la (trans)formation des inégalités de développement. On a adopté pour cela une approche « spatialisante » à une échelle locale. Nous avons ainsi fait le pari d’aborder les inégalités de développement à l’échelle des villages du Sud de l’Inde, en considérant leurs structures spatiales avant même d’étudier leurs dimensions socio-économiques, nécessairement imbriquées, mais laissées comme hypothèse secondaire[1]. Cette posture scientifique est celle de l’analyse spatiale (Haining, 2003, Goodchild, Janelle, 2004) que l’on peut résumer par la formule « space matters ». L’hypothèse centrale soutenant ces travaux est celle du rôle des interactions spatiales comme élément explicatif des inégalités, et celui de l’espace comme « frein » à ces interactions (Pini, 1992, Pumain, St Julien, 2001).
Les approches suivies sont multiples, et les outils à notre disposition nombreux. La démarche la plus classique, préalable au travail sur la dimension spatiale, est celle de la cartographie. Mais, là encore, les possibilités (échelles, données, représentations, etc.) et les contraintes (nombre d’unités, lisibilité, robustesse des résultats…) sont nombreuses, et nous ont amenés à faire des choix pour présenter, à travers un atlas, une première photographie de l’Inde du Sud. La seconde démarche, plus originale, vise à étudier les structures spatiales des phénomènes. Nous avons donc développé un travail sur l’autocorrélation spatiale, la variographie et surtout les analyses locales d’autocorrélation spatiale des phénomènes observés.
1.1. Pourquoi l’espace ? Diffusion et répartition
L’intégration de l’espace dans les sciences sociales est ancienne. Elle a cependant toujours des difficultés à être acceptée, notamment parce que l’intégration de l’espace pose finalement plus de problèmes qu’elle n’en résout (voir Derycke, 1994 à propos de l’intégration de l’espace dans la modélisation économique). Néanmoins, la dimension spatiale des inégalités de développement a déjà été pensée. Ainsi, la notion de « centre-périphérie » vient de l’économie (voir à ce propos Krugman, 2000), et a ensuite été réinterprétée dans l’espace géographique. Les notions de « centre » et de « centralité » sont étudiées aussi bien par les géographes que par les économistes. Les échanges conceptuels entre géographie économique et économie spatiale sont fréquents. Ainsi la diffusion spatiale des innovations, concept géographique ancien, a été reprise pour réinterpréter en termes spatiaux la théorie économique des pôles de croissance. En sociologie, les modalités d’interrogation du concept d’urbanisation sont différentes de celles de la géographie, les géographes s’interrogeant plus sur la dimension spatiale du passage de l’urbain au rural (en termes de conditions et de conséquences notamment).
1.1.1. A la source des déséquilibres spatiaux : la centralité
En 1973, dans son ouvrage « Le développement inégal », Samir Amin utilise le binôme centre-périphérie pour décrire, dans une vision engagée des inégalités mondiales du développement économique, l’opposition que l’on nomme aujourd’hui Nord-Sud. Cette association de termes est alors pensée dans un cadre économique, proche du marxisme, où le centre est exploitant et la périphérie exploitée. La dimension spatiale est secondaire et plutôt utilisée de façon métaphorique. Mais cette approche ouvre la voie à une réflexion plus globale sur les rapports entre sociétés (et espaces) dominantes et dominées, mettant en place un transfert du social au spatial (Di Méo, 1991).
Ce schéma s’applique d’ailleurs à plusieurs échelles, et c’est une de ses richesses. Ainsi, s’il exprime l’antagonisme entre pays développés et pays en développement, il est aussi adapté pour comprendre l’opposition (considérée encore en termes de domination) entre ville (centre) et campagne (périphérie). Cette opposition dialectique a donc été reprise en géographie, car sa puissance évocatrice est forte. De plus, sa capacité à décrire de façon binaire les phénomènes observés, quelle que soit l’échelle, est fort intéressante. Néanmoins cette approche est aujourd’hui dépassée. On sait que le centre peut avoir une partie de sa population dominée (et même une part de son espace), et que la périphérie n’est pas constituée uniquement d’exclus[2].
Dans un contexte plus large, le phénomène centre-périphérie peut être vu comme un cas particulier et manichéen du concept de centralité. La centralité est une perception subjective de l’espace. On définit à travers elle un point comme étant particulier et se différenciant des points qui l’entourent (Huriot, Perreur, 1994). Ce point est alors appelé centre. Il sert de référent pour structurer l’espace. N’oublions pas cependant que la centralité n’est ni absolue, ni totalisante. Elle est au contraire relative et contextualisée : par le jeu de l’échelle, elle est relative à un espace ; elle est contextualisée car le point central est défini en fonction de l’étude. Dans ce cadre, on peut comprendre la théorie des lieux centraux, énoncée originellement par W. Christaller dans les années 1930, comme un ensemble hiérarchisé de centres, dont la centralité est relative au niveau d’observation (qui définit le niveau de centralité) et dépendante du contexte (c’est-à-dire, dans son étude, des fonctions urbaines).
Pour expliquer la création de centres, on peut reprendre la théorie économique des économies d’agglomération (Catin, 1994). En raccourci, elle considère l’agglomération comme un facteur d’économie, permettant un avantage relatif par rapport aux zones non agglomérées[3]. L’agglomération, en se différenciant des zones non agglomérées, se définit ainsi comme un centre. De plus, ce centre se place alors comme un objet concurrent et compétitif des autres objets, ce qui lui permet d’attirer encore plus et de renforcer sa position. C’est ce qu’Huriot et Perreur nomment la « centralité-attractivité » (Huriot, Perreur, 1994: 50). Cette réflexion, issue de l’économie, s’adapte aussi à la compréhension d’autres aspects, qu’ils soient sociaux ou culturels.
Si le centre attire, il ne peut néanmoins tout accueillir, et il se crée alors une hiérarchie des objets accueillis au centre (Thisse, 2002), les autres objets s’organisant autour de lui, suivant une forme non nécessairement concentrique, car d’autres facteurs peuvent influer. Le centre redistribue alors autour de lui une partie des objets (effet de back wash) et accroît son rôle dans l’organisation géographique de l’espace. Mais le centre, outre sa fonction attractive, peut aussi être un point de départ. C’est la « Centralité-diffusion » définie par Huriot et Perreur (Ibid.). En effet, le centre est aussi au cœur de la diffusion spatiale des innovations (on se réfère évidemment au travail d’Hägerstrand, 1967). Ainsi lorsqu’une innovation apparaît en un point donné, celui-ci se démarque des autres et constitue, selon la définition, un centre. Celui-ci va alors transmettre l’innovation (ou l’information) vers d’autres points (effet de spill over).
C’est cette perception du centre diffuseur qui est à la base de la théorie des pôles de croissance. F. Perroux, dans les années 1950, explique que « la croissance n’apparaît pas partout à la fois ; elle se manifeste en certains points, ou pôles de croissance, avec des intensités variables ; elle se répand par divers canaux avec des effets terminaux variables pour l’ensemble de l’économie » (cité par Manzagol, 1992 : 496). Une des idées maîtresses de la théorie des pôles de croissance est celle d’industrie industrialisante : une entreprise innove dans un point de l’espace, son développement entraîne celui des entreprises qui l’entourent (par augmentation de la consommation locale) et celles avec lesquelles elle travaille (par augmentation de la demande de production). Ce modèle théorique a été mis en application dans les années 1970 dans le cadre de plusieurs politiques de décentralisation, en Inde notamment. L’une des critiques de cette théorie se fonde sur l’angle de vue adopté. En effet, à l’inverse de l’idée d’une industrialisation provoquant l’urbanisation par un effet d’agglomération des individus autour d’elle, on peut envisager que ce sont les espaces peuplés qui fabriqueraient de l’industrie (Cassidy, 1997). Cela expliquerait d’ailleurs assez bien l’échec des implantations d’industries industrialisantes dans certaines zones (notamment en Afrique), le pôle de croissance n’ayant pas pu créer d’effet d’entraînement sur son hinterland, trop peu peuplé. Mais finalement, et à la suite de Berry (1973), nous considérons que la théorie des pôles de croissance n’est qu’un cas particulier de diffusion de l’innovation.
1.1.2. La diffusion comme élément de transformation de l’espace
« Etymologiquement, la diffusion correspond à tous les déplacements qui, quelle qu’en soit la force motrice, cherchent à se répandre de manière homogène dans un système, et tendent à faire passer celui-ci d’un état d’équilibre à un autre état d’équilibre » (Saint Julien, 1992 : 559).
Un phénomène d’innovation se définit comme nouveau, irréversible, et modifiant la dynamique des systèmes dans lesquels il opère (donc sans rapport avec un phénomène de mode). Les sciences sociales interprètent ce type de processus comme endogène (dans une perspective plutôt weberienne) ou exogène (dans la tradition de Durkheim). On peut cependant adopter une position plus nuancée en affirmant qu’un phénomène de diffusion est à la fois le fruit d’un élément exogène, puisqu’il est nouveau, et endogène, puisqu’il est accepté par le système. On rappellera que la diffusion peut prendre plusieurs formes : sociale et spatiale notamment. Les « déplacements » selon la définition de Thérèse Saint Julien peuvent être à la fois dans l’espace ou, de façon plus imagée, à l’intérieur d’une société. Cela correspond par exemple à la notion de « capillarité sociale » développée par Arsène Dumont (Tabutin, 2000). Les deux formes se complètent, même si le social est d’abord le terrain privilégié du sociologue et le spatial celui du géographe.
Pour bien comprendre comment fonctionne le phénomène de diffusion spatiale, il faut en distinguer les différents éléments et évaluer le rôle de chacun. Nous en distinguerons six, en nous appuyant sur les travaux de Thérèse Saint-Julien (1985) :
1) Les facteurs exogènes sont à la base de l’innovation, puisque ce sont eux qui l’apportent dans le système.
2) La force de la combinaison innovante est plus difficile à définir. Il s’agit en fait de l’innovation observée et des phénomènes associés. Par exemple, si l’on observe la baisse de la fécondité comme innovation, la combinaison innovante est l’alphabétisation, le statut de la femme, etc.
3) L’aptitude au déplacement est la capacité du phénomène à se propager dans l’espace. Elle dépend de deux facteurs : la distance, tout d’abord, qui peut être physique, sociale, économique, culturelle… et les canaux ensuite (qui sont souvent des réseaux : routiers, sociaux, etc.). Ces deux facteurs suffisent souvent à expliquer une bonne part des vitesses différentielles de propagation de l’innovation.
4) La force de propagation ne doit pas être confondue avec l’aptitude au déplacement. Elle marque surtout le rôle des foyers émetteurs. Plus ce foyer est puissant, plus la diffusion peut aller loin, et vite.
5) Le temps de propagation est l’élément le plus important pour comprendre la vitesse de diffusion du phénomène. Sa mesure est simple : il s’agit de compter le temps écoulé entre l’amorce de la diffusion et la saturation du système (voir Figure 1). Mais il n’y a pas d’échelle unique, et la comparaison de plusieurs phénomènes reste de l’appréciation du chercheur.
6) Le milieu d’accueil n’est pas à négliger, puisqu’il marque le rôle des récepteurs, c’est-à-dire ici de la population adoptant ou non les nouvelles normes. Cet élément permet souvent de mettre en valeur la structure du système de peuplement, l’innovation se déplaçant généralement plus vite quand la population est plus dense.
La diffusion spatiale, comme tout processus géographique, reste très liée à la notion d’échelle et de niveau d’agrégation. Elle peut s’analyser à différentes échelles, faisant alors ressortir différents acteurs de la propagation de l’innovation.
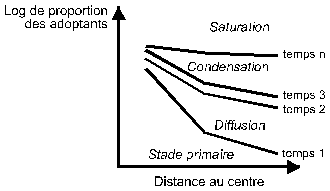 |
Figure 1 : les étapes de la diffusion spatiale dans le temps. D’après T. Hägerstrand (1953)
Une analyse régionale désagrégée, qui prend les communes rurales comme référents, semble la meilleure échelle pour mettre en valeur les objets suscitant la diffusion (les villes, par exemple) ainsi que les structures spatiales du milieu d’accueil (les réseaux). On comprend pourquoi cette échelle a longtemps été privilégiée dans la géographie française, et particulièrement chez les « tropicalistes ». Pierre Gourou, représentant historique de cette école, avait fait de l’échelle régionale son niveau d’analyse privilégié, et c’est sans aucun doute pour la raison évoquée, à savoir la bonne vision des microstructures et la mise en valeur du rôle des encadrements.
L’échelle macro et agrégée ne permet plus, quant à elle, de distinguer le rôle des individus et des contacts directs, mais les grands réseaux de communication et les formes des systèmes de peuplement (grandes aires culturelles par exemple) sont clairement identifiables.
Lorsque l’on envisage d’expliquer la géographie d’un phénomène par la diffusion, il convient alors de rappeler qu’outre la diffusion par contagion, c’est-à-dire de proche en proche, comme nous venons de la décrire, il peut exister un phénomène de diffusion hiérarchique. Cette dernière n’agit pas en fonction de la proximité spatiale comme nous l’avons vu, mais en fonction d’une organisation hiérarchique (système de villes par exemple).
Ces observations doivent maintenant laisser la place aux aspects techniques de notre travail sur un SIG indien permettant précisément la mise en œuvre de ces notions théoriques. Les sections qui suivent décrivent notre base de travail et les modifications qu’on lui apportées.
1.2. Description générale de la base
1.2.1. Spatialiser les données censitaires
Pour un travail exhaustif à l’échelle villageoise, le recensement constitue en Inde la seule source disponible. Son unité de base est la commune rurale (revenue village). Ces villages fiscaux peuvent comprendre plusieurs hameaux, qui seront alors traités comme une seule unité administrative. On notera tout de suite deux biais liés à ce découpage. D'abord, il est impossible de différencier les formes d'habitat groupé et dispersé. Ensuite la comparaison inter-Etats est impossible puisque les découpages sont dépendants de choix politiques locaux.
Néanmoins, son utilisation demeure nécessaire, et finalement assez efficace pour ne pas être rejetée (Oliveau, 2004 et 2005). La trame offerte est en effet bien adaptée à l’exercice auquel nous souhaitons nous livrer. De plus, le recensement offre des cartes de localisation des villages, qui, si elles sont de mauvaise qualité, permettent tout de même le géoréférencement nécessaire à la mise en place d’une base de données et au calcul de distance. Par contre, les informations offertes par le recensement restent loin de la qualité et du détail des enquêtes du NFHS[4] ou du NCAER[5]. Mais il s’agit bien sûr d’un exercice totalement différent. Certaines questions ne sont pas posées, comme celles concernant le revenu, ou les mobilités (même si un effort a été fait dans cette direction pour le recensement de 2001). Les définitions floues, en ce qui concerne l’emploi tertiaire par exemple, et le manque de fiabilité des données infrastructurelles, particulièrement celles concernant l’occupation du sol, en font une source à manier avec prudence. Il ne faut jamais perdre de vue la signification réelle des données et la limite de leur utilisation. Ainsi, les données ont souvent un sens différent de celui qu’on leur donnerait ailleurs. Par exemple, le travail des femmes n’est pas une marque d’émancipation, mais la marque de la pauvreté, car il concerne avant tout les milieux ruraux, et ces travaux sont les plus durs et pas forcément les mieux payés. Le travail des femmes ne signifie pas forcément, pour elles, une plus grande autonomie.
L’exploitation des données du recensement dans une perspective d’analyse spatiale nécessite leur mise en espace (géoréférencement) afin de pouvoir utiliser les SIG (Système d’Information Géographique) et autres logiciels de calculs géostatistiques.
Dans ce cadre, nous avons utilisé la base de données développée au sein du programme « population et espace en Inde du Sud » à l’Institut Français de Pondichéry. Ce SIG a été construit à partir de l’ensemble des localités des quatre Etats de l’Inde du Sud. Nous ne reprendrons donc ici que les grandes lignes du travail, la base de données ayant fait l’objet d’une publication sur CD-Rom (Guilmoto, Oliveau, 2000) et d’une description partielle dans Guilmoto et al. (2002).
1.2.2. L’accès aux cartes, toujours un problème en Inde.
Si la population indienne est bien suivie, l’espace indien est encore mal connu, car les cartes constituent toujours un élément considéré comme hautement stratégique par le gouvernement. Ainsi, la diffusion des cartes topographiques mentionnant des sites considérés comme stratégiques (bases militaires et installations nucléaires, mais également les ouvrages d'art ainsi qu’une bande côtière de plus de 50 km à l’intérieur des terres) est interdite. Pour les Etats littoraux, comme les quatre Etats du Sud de l’Inde, une partie des cartes topographiques n’est donc pas officiellement disponible. Par ailleurs, la production de nouvelles cartes est soumise à de nombreux contrôles administratifs et stratégiques qui ralentissent leur diffusion.
Les cartes publiées sont, par conséquent, peu nombreuses et incomplètes. Il est impossible de situer tous les villages, ni même toutes les infrastructures (les barrages, par exemple, puisqu’ils sont classés comme lieux stratégiques). Il n’existe d’ailleurs que deux sources fournissant des cartes en Inde: le Survey of India pour les fonds topographiques, et le recensement indien dont les volumes par district fournissent les découpages administratifs, repris d'ailleurs des fonds du Survey of India. Hormis quelques plans de grandes villes récemment publiés, toutes les cartes en Inde reposent sur les sources du Survey of India et de ses dérivés.
Pour construire notre SIG, nous avons donc dû avoir recours à deux sources : les cartes du recensement d’une part, qui présentent l'avantage de fournir une localisation exhaustive des unités de recensement, à savoir les villages fiscaux, les cartes topographiques britanniques d’autre part. Les cartes du Census sont publiées dans les District Census Handbook. Elles ont donc suivi le rythme (lent) de leur parution, les derniers volumes pour le Sud de l’Inde étant sortis en août 2000. Les cartes fournies sont assez grossières, même si elles localisent précisément les villages. Pour les géoréférencer, il a fallu les coupler avec les cartes topographiques anglaises. Celles-ci datent de la colonisation et sont accessibles plus aisément aux chercheurs[6]. Elles datent toutes d’avant la décolonisation, et pour beaucoup du début du 20ème siècle. Malgré leur âge, elles permettent d’identifier des points remarquables autorisant le géoréférencement. Nous avions effectué des tests à cet effet en 1998, et ils s’étaient avérés concluants (Oliveau, 1998).
Le travail de saisie des données a pris plus de deux ans, puisqu’il a fallu saisir les 16 780 villages et les 262 villes tamoules –ainsi que le réseau routier et les limites administratives supérieures (taluks et districts). A l’échelle du programme « Population et espace », ce sont 75 523 villages, 843 unités urbaines et toutes les routes de l’Inde du Sud qui ont été saisis, couvrant 636 000 km² et 197 249 763 habitants.
Il convient, avant d’aller plus loin, de souligner deux faiblesses de cette base de données. D’abord, le recensement étant le seul organisme à fournir la cartographie exhaustive des villages, la source est unique. Les vérifications et corrections possibles restent donc limitées. Nous avons effectué une série de tests statistiques, des tests logiques sur les données ainsi que des vérifications croisées entre les données numériques et les publications sur papier, quand elles étaient disponibles. La base statistique finale du South India Fertility Project, si elle n’est pas parfaite, est finalement bien meilleure que les publications du recensement.
Ensuite, les sources cartographiques étant limitées et parfois de qualité moyenne, il existe une erreur de précision dans les localisations. Néanmoins, cette erreur est, d’après nos vérifications sur le terrain effectuées avec un GPS, inférieure à 500 mètres, et parfois inférieure à 250 mètres. A cette qualité de précision, on doit ajouter l’exactitude du fond, elle aussi remarquable. On distingue la précision, c’est-à-dire l’erreur de mesure (qui s’exprime en longueur ou en pourcentage), de l’exactitude qui marque la ressemblance entre la carte et la réalité. Une carte peut être très précise, mais complètement fausse et vice-versa (Didier, 1990). Les cartes que l’on trouve en Inde sont souvent inexactes et imprécises !
On rappellera ainsi que les sources cartographiques informatisées sur la population indienne sont quasi-inexistantes. Une source comme le DCW (Digital Chart of the World [7]) est moins précise (sa définition est de 1 : 1 000 000), plus ancienne (les relevés pour l’Inde datent des années 1970) et contient plus d’erreurs : le repérage à partir d’images satellites ne « voit » pas les infrastructures existantes sous les végétaux (routes en forêt ou bordées d’arbres), de même qu’il n’est pas capable de différencier les infrastructures abandonnées de celles encore utilisées[8].
1.2.3. Une base de données multidimensionnelle
Pour bien comprendre les informations disponibles, et donc le travail envisageable à cette échelle, il convient de présenter la base de données de façon plus détaillée : huit couches de données sont présentes dans le SIG. La première concerne bien sûr les 75 522 villages du Sud de l’Inde. La seconde regroupe les 843 villes, puis l’on a ensuite les échelons administratifs supérieurs : taluks (équivalent au NUTS 3 européens) et districts (équivalent au NUTS 2 européens). Au niveau des infrastructures, la base possède une couche concernant le réseau routier et une autre le réseau ferroviaire. L’hydrographie constitue une septième couche. Et enfin, la base de données comprend un MNT d’une résolution de 500 m. Dans le cadre du projet EMIS, des informations renseignant sur le climat (températures et précipitations) sont venues compléter ce SIG.
Tableau 1 : Couches de données disponibles
Couches |
Format |
Informations disponibles |
Villages |
Points |
Primary Census Abstract, Village Directory |
Villes |
Polygones |
Primary Census Abstract |
Taluks |
Polygones |
Primary Census Abstract |
Districts |
Polygones |
Primary Census Abstract |
Réseau routier |
Lignes |
Hiérarchie des routes (locale, régionale, nationale) |
Réseau ferroviaire |
Lignes |
- |
Hydrographie |
Lignes, Polygones |
Pérennité |
MNT |
Grille |
Altitude par zone de 500m x 500m |
Climat |
Points |
Température et Précipitation par mois |
La publication des DCH a débuté après le recensement de 1951. Elle se place dans la continuité de la tradition des publications britanniques, dans le sens où chaque volume commence par une présentation générale du district, rappelant sur une cinquantaine de pages les traits majeurs qui le caractérisent, à travers des données agrégées (statistiques sociales, culturelles, démographiques et économiques), une carte globale, une description des caractéristiques physiques majeures, des informations sur les principaux lieux touristiques ainsi que d’autres informations de type administratif (changement dans les limites administratives, services existant etc.). On retrouve donc, en condensé, les informations contenues dans les district gazetteers de jadis, recueil d’informations de toute nature publiées à l’époque coloniale.
Le Village Directory répertorie les infrastructures présentes dans les villages, à savoir :
· Le nombre et le type d’équipements scolaires et médicaux, ou la distance la plus courte à l’unité possédant cette infrastructure.
· Les équipements routiers (type de routes conduisant au village, disponibilité d’arrêt de bus, de station de taxi, etc.)
· La présence d’infrastructures de télécommunication (bureau de poste, téléphone, fax, etc.)
· La disponibilité ou non en eau potable, et le moyen de la distribuer (pompes, puits, etc.) ; La distance à la source d’eau potable la plus proche quand elle n’est pas disponible dans le village.
· La disponibilité en énergie électrique et sa destination (usage domestique, agricole ou industriel)
· L’occupation du sol (surfaces forestières, agricoles -irriguées ou non-, etc.) et, le cas échéant, le type d’irrigation.
· La distance à la ville la plus proche et le nom de celle-ci
Le Primary Census Abstract (PCA) contient quant à lui les informations par sexe relatives aux populations, que l’on peut classer en différentes catégories :
· Données démographiques : nombre de logements, nombre de logements occupés, population totale, population masculine et féminine
· Données socioculturelles : population dalit, population tribale, niveau d’alphabétisation général.
· Données économiques générales : nombre d’actifs, nombre d’actifs partiels, nombre de personnes sans emploi.
· Données sur l’emploi : le recensement distingue dix catégories d’actifs :
- Les propriétaires cultivateurs
- Les employés agricoles
- Les autres actifs du secteur primaire (pêcheurs, chasseurs, forestiers, employés dans les plantations)
- Les mineurs et employés dans les carrières
- Les artisans et employés d’industrie à domicile (household industry)
- Les employés d’entreprises industrielles (non household industry)
- Les employés du bâtiment
- Les employés dans le commerce
- Les employés dans le stockage, la manutention et le transport
- Les autres actifs du tertiaire (services, fonctionnaires, etc.).
[1] Par exemple, le niveau de d’alphabétisation est fonction de la distance à une structure d’enseignement de qualité (effet spatial) plus que fonction de la présence d’une école primaire (indicateur socio-économique de développement).
[2] Le chapitre d’Alain Reynaud dans l’Encyclopédie de géographie (Reynaud, 1992) est remarquable par sa précision et ses nuances dans la définition des deux concepts de centre et de périphérie.
[3] D’où les quolibets, cités par Krugman (2000 : 50), que l’on a pu entendre à propos de cette vision des choses : « Alors, les économistes croient que les entreprises s’agglomèrent à cause des économies d’agglomérations ? ».
[4] Nom de l’enquête DHS en Inde. http://www.nfhsindia.org/anfhs.html
[5] Voir leur site : http://www.ncaer.org/
[6] L’Institut Français de Pondichéry possède quasiment toute la couverture du sud de l’Inde.
[7] Le Digital Chart of the World est une base de données géographiques à l’échelle mondiale. Elle a été développée par l’entreprise ESRI pour l’agence de cartographie de la défense américaine. La source primaire est l’ONC (Operational Navigation Chart).
[8] propos de la qualité du DCW, voir Kraak, Ormeling (1996 : 207).