2. Une agrégation flexible
Au-delà des problèmes techniques propres à sa mise en place, la création de la base a posé un réel défi dans sa complexité. Elle repose en effet sur une infrastructure administrative qui est loin d’être cohérente de région à région. Nous nous intéresserons ici avant tout aux unités rurales, car le traitement des unités urbaines nous a semblé moins important, notamment dans la perspective de notre étude de la « surface socio-économique » de l’Inde du sud.
2.1. Une base trop fine ou trop riche ?
Nous avons en effet rencontré très vite des difficultés dans la gestion exhaustive de la base de données spatialisée, tenant notamment à nos différents impératifs de :
· Lisibilité cartographique
· Calculabilité
· Hétérogénéité des unités
· Robustesse statistique des indicateurs
Nous traiterons de ces deux premières gammes de problèmes ensemble, alors que les deux dernières sont d’un tout autre ordre.
Notons au passage que les questions propres à la qualité intrinsèque des données recueillies par le recensement indien sont ici hors de notre propos, même s’il est évident que pour les observateurs de la société indienne, elles sont essentielles pour ajuster notre réflexion. Ainsi, la qualité des données ou de l’enregistrement censitaire ont conditionné les choix opérés dans l’identification des indicateurs. Mais ces questions relèvent du domaine « sémantique » que nous n’abordons pas dans le cadre du projet EMIS.
2.1.1. Problème du nombre d’unités
Il n’est guère réaliste de vouloir cartographier simultanément 70.000 unités. Même des cartes très fines, reproduites sur des supports de qualité (page A4 couleur, diapositives), ne peuvent offrir à l’œil que quelques milliers de points ou de surfaces en contraste. Toute échelle plus fine est illusoire.
En outre, le problème de la lourdeur des calculs devient réel. Si les outils de SIG ou de traitement statistique n’ont guère de difficultés aujourd’hui à traiter 100.000 unités, il en va autrement des calculs géostatistiques. En effet, un grand nombre des protocoles géostatistiques examine le rapport des unités à leur voisinage, procédant notamment par traitement matriciel. Ainsi le krigeage mobilise pour chacune des unités un ensemble de voisins dans un rayon dont la taille doit être raisonnable pour asseoir la qualité des estimateurs. Or, un simple calcul montre qu’un village sud indien compte en moyenne 1020 villages dans un rayon de 50 kilomètres. Ce qui imposerait des krigeages très lourds, si l’on prend en compte un tel rayon, car ils seraient basés sur des matrices de taille 1000 x 1000.
On fera la même observation en matière de calcul d’autocorrélation spatiale : la matrice complète des paires d’enregistrements (70.000² / 2) est de taille considérable et décourage les traitements exhaustifs.
La première solution à cette difficulté consiste naturellement à se restreindre à des traitements partiels, sur des aires plus limitées contenant par exemple moins de 5000 unités. On se trouve alors forcé à renoncer à un traitement exhaustif à visée comparative sur l’ensemble du territoire sud-indien. Mais comme on va le voir dans la section suivante, cette solution au-delà des limites qu’elle présente à notre entreprise n’est guère viable pour des raisons d’une autre nature.
2.1.2. Problème de taille des unités
Les unités administratives rassemblées dans notre SIG ont des origines très hétérogènes. S’il n’est pas le lieu ici d’amorcer une histoire administrative de l’Inde, notons toutefois que l’Inde du sud a une histoire politique extrêmement fragmentée. Avant l’indépendance, elle se trouvait divisée en une large partie sous administration britannique, mais également un grand nombre d’Etats princiers autonomes parmi lesquels les plus célèbres sont ceux d’Hyderabad (le Nizam), du Travancore, de Cochin et de Mysore. A l’intérieur de l’Inde britannique (en l’occurrence la Présidence de Madras), l’administration coloniale n’a pu que recomposer une architecture principalement fiscale aux échelles supérieures des districts et des « taluks », que l’on pourrait comparer respectivement à des régions et des départements français.
Cette structure en districts et taluks (alias tehsils, mandals etc.), régulièrement enrichie et complexifiée durant les dernières décennies, reste homogène avec des unités de taille et de peuplement comparables. Mais le semis des milliers d’unités villageoises n’a guère été modifié par le régime colonial et les autorités de l’Inde indépendante. Leur définition repose sur deux principes très distincts : l’histoire politique locale et l’écologie du peuplement. Cette dernière découle elle-même de la rencontre entre des principes sociologiques (distribution et regroupement des castes) et géographiques (organisation du milieu et répartition des terroirs) d’organisation de peuplement.
On prendra par exemple pour critère de comparaison interrégionale des villages la taille de la population totale. En nous limitant ici aux quatre Etats de l’Inde du sud, la figure qui suit montre la répartition des localités selon leur taille. On voit que s’opposent par exemple le Kérala d’une part, doté de gros villages de plus de 10.000 habitants en moyenne, et les autres Etats d’autre part, comme le Karnataka où abondent les hameaux comptant moins de 1000 habitants (ces derniers représentant plus des deux tiers des localités de l’Etat). Une analyse plus fine, à l’intérieur des Etats, montrerait des regroupements géographiques plus accentués encore, notamment des zones de micro-localités caractérisées aussi bien par un habitat dispersé et épars (zones tribales) que concentré, mais administrativement morcelé (région historique de Mysore). Il apparaît donc que de nombreuses régions sont découpées en micro-unités qu’il serait bien risqué de comparer aux villages plus compacts du sud. On ajoutera pour brouiller le tableau que la taille des villages ne correspond que très imparfaitement à la densité démographique moyenne ou même encore au caractère concentré des établissements humains.
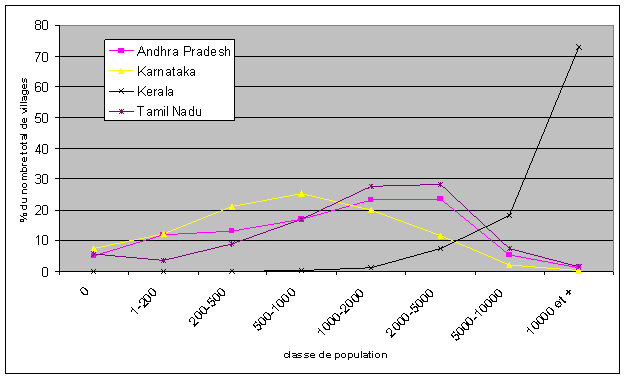
Figure 2 : Répartition des villages par taille dans les quatre Etats indiens
A ces difficultés s’est rajouté le problème proprement statistique lié aux faibles populations. De nombreux indices utilisés pour caractériser les localités s’avèrent instables quand ils sont calculés sur de petits effectifs. On en prendra pour exemple le calcul de l’écart type du rapport enfants/femmes[9]. On voit que cette variabilité de l’indice augmente quand la population des villages diminue, atteignant des valeurs atypiques pour les villages de moins de 500 habitants. Il n’y a sans doute pas de seuil statistique identifiable, d’autant que la moindre variabilité observée dans les villages les plus peuplés peut être due à des facteurs d’un autre ordre (rôle propre au Kérala). Toutefois, il peut sembler raisonnable de se méfier des villages comptant moins de 500 habitants en raison de la présence de valeurs extrêmes, sans lien avec la réalité du phénomène à étudier.
Tableau 2 : Distribution des rapports enfants/femme selon la taille des villages
Classe de taille |
moyenne |
Écart-type |
Coefficient de variation |
1-200 hab. |
0.458 |
0.358 |
78.2% |
200-500 |
0.420 |
0.137 |
32.5% |
500-1000 |
0.417 |
0.116 |
27.7% |
1000-2000 |
0.406 |
0.103 |
25.3% |
2000-5000 |
0.389 |
0.093 |
23.8% |
5000-10000 |
0.366 |
0.086 |
23.4% |
10000 et + |
0.328 |
0.081 |
24.8% |
Total |
0.408 |
0.158 |
38.6% |
2.2. Agréger
Ces dernières observations suggèrent qu’une étude réduite à des seules sous-régions, afin de pallier le nombre parfois prohibitif pour la cartographie et le traitement géostatistique, bute à son tour sur la forte hétérogénéité du peuplement et la présence d’unités villageoises trop peu peuplées. Le découpage administratif n’est toutefois pas de nature à offrir une solution « naturelle » d’agrégation, d’abord parce qu’il est très limité. On passe ainsi de 75000 villages, au niveau 0, à 1513 taluks ruraux au niveau 1, divisant ainsi notre partition par un facteur de 50. De plus, ce découpage est imparfait, en raison du cas particulier de l’Andhra Pradesh qui a, dans les années 1980, opéré un redécoupage de ces taluks originaux en 1100 « mandals » de taille beaucoup plus réduite que les 413 taluks du reste de l’Inde. De ce fait, alors que les taluks sud-indiens sont de taille relativement hétérogènes, la population moyenne des mandals de l’Andhra (44000 habitants) est environ cinq fois plus petite que celle des autres taluks (216000), ce qui rend les confrontations statistiques ou cartographiques malaisées.
On a par conséquent dû opter pour une reclassification automatique, par réagrégation des villages. L’objectif était, rappelons-le, triple : réduire la taille de notre échantillon de référence, réduire l’hétérogénéité dans la dimension des unités de mesure et réduire la part relative des micro-unités statistiquement instables. La décision est naturellement délicate, car le risque est réel en diminuant notre échantillon de réduire d’autant la variance de nos données, effaçant ainsi une part de la richesse de notre base en « moyennant » les valeurs. L’hétérogénéité à l’échelle villageoise est en effet la combinaison de deux composantes : le pur « bruit statistique » à éliminer et les réelles micro-variations locales dont la présence nous intéresse.
2.2.1. Méthodes et résultats
Différentes méthodes s’offraient à nous, privilégiant des critères particuliers pour le protocole d’agrégation des localités censitaires. En résumé, indiquons dès à présent que nous n’avons pas souhaité opérer un regroupement selon un critère proprement démographique, en réagrégeant par exemple les populations par différents blocs de 20.000 personnes. Une telle méthode (appelée parfois méthode des potentiels de population) devrait être appliquée à un paysage marqué par des fortes variations dans la densité du peuplement, variant de moins de 30 habitants au km² (par exemple dans les zones forestières des Ghâts) à plus de 1500 dans les régions rurales très peuplées du Kérala. Elle tendrait donc à dénaturer notre découpage régional, créant des unités de superficie extrêmement disparates. A titre d’exemple, on considérera un « gros village» typique du Kerala, recouvrant 31 km², avec 35.000 habitants. Notons alors que dans les régions septentrionales de l’Andhra Pradesh, il faudrait pour atteindre une telle population assembler 175 localités différentes réparties sur près de 2000 km², soit un espace 70 fois plus vaste que celui du village kéralais. On imagine alors les disparités spatiales d’une partition fondée sur une équi-population.
Nous avons donc choisi de privilégier la dimension spatiale, mesurée par la seule distance euclidienne. Cette dernière reste le meilleur (ou le moins mauvais) « proxy » pour l’intensité des échanges sociaux, qui constitue précisément le moteur de la transmission des comportements économiques ou sociaux dans notre schéma interprétatif[10]. De ce fait, nous avons décidé de redécouper l’espace sud-indien en poches de taille identique, appelés ici « clusters ». Nous nous sommes fixés différentes échelles de regroupement : 2, 5, 10 et 20 km. L’existence de niveaux variables de partition nous permet de choisir la grille appropriée pour chaque analyse, en fonction par exemple du nombre de clusters souhaité.
Décrivons d’abord la méthodologie suivie. En premier lieu, partant du semis villageois exhaustif (y compris les villages inhabités, nombreux dans les zones forestières), nous avons procédé à une première agrégation automatique, réduisant l’échantillon originel à un nouvel ensemble de points d’agrégation en fixant la distance d’agrégation : tous les points à moins de n km les uns des autres sont alors fusionnés. Le résultat est alors un semis beaucoup plus régulier, puisque les localités proches ont été agrégées en leur centre géométrique. A partir de ce nouveau semis, nous créons des polygones de Thiessen/Voronoi qui serviront de base à notre famille de clusters. Nous reprenons enfin la base d’origine et regroupons tous les villages situés à l’intérieur des polygones de Thiessen, additionnant ou moyennant les valeurs individuelles selon la nature de la centaine de variables disponibles. Cette même procédure est conduite quatre fois, afin de réaliser un regroupement selon les échelles spatiales choisies (2, 5, 10 et 20 km).
La carte reproduite ici (nord de l’Andhra Pradesh) montre la répartition des villages d’origine (en noir), les points d’agrégation sur des rayons de 10 km et les polygones de Thiessen correspondant. Ces polygones constituent les limites des clusters et on voit que leur structure, sans être parfaite (notamment sur les bords), offre un découpage beaucoup plus régulier que le semis de points d’origine. On notera également que les emplacements des points d’agrégation sur lesquels sont construits les polygones de Thiessen sont influencés par la distribution spatiale des villages, sans naturellement l’épouser entièrement. La carte qui suit est identique, mais représente les clusters à 5 km qui sont beaucoup plus petits et nombreux.
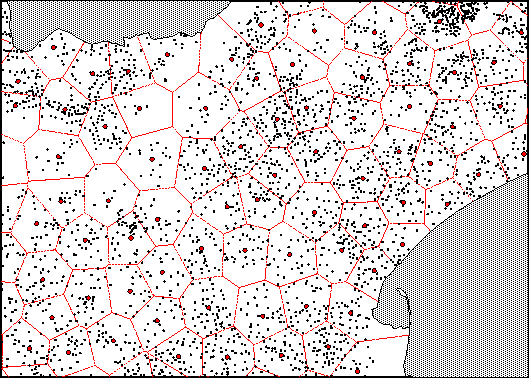 |
| Figure 3 : Villages d’origine, points d’agrégation à 10 km et polygone de Thiessen correspondant. |
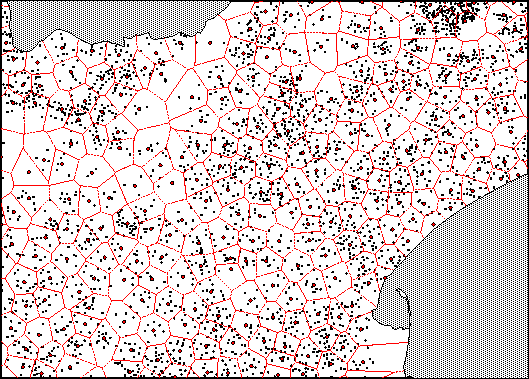 |
| Figure 4 : Villages d’origine, points d’agrégation à 5 km et polygone de Thiessen correspondant. |
2.2.2. Effets de la clusterisation
Quoique lourde en termes calculatoires (combinant analyse statistique et réagrégation statistique), cette procédure va donner une nouvelle partition de l’Inde du sud, très régulière en terme spatial et indifférente aux frontières administratives, comme les limites d’Etat, que nous avons choisi volontairement d’ignorer. Le tableau qui suit résume à la fois les résultats obtenus et les avantages de la méthode.
On voit en premier lieu que le nombre d’unités décroît régulièrement, selon l’échelle de regroupement de nos clusters, alors qu’augmente la taille moyenne des aires correspondantes. En second lieu, on observe la forte décroissance de la variance relative (coefficient de variation), à la fois des populations des unités et des aires. La décroissance est plus rapide pour ces dernières, puisque cela était le critère d’agrégation, mais elle n’est pas négligeable pour les populations en dépit des très fortes variations de densité que notre procédure n’entend aucunement gommer. On note en outre la diminution régulière des unités vides ou de population faibles (inférieures à 500 habitants) : elles représentaient 30% de l’échantillon d’origine et n’en font plus que 1% après regroupement à 5 km.
Tableau 3 : Caractéristiques des villages et clusters
Villages habités |
Types de cluster |
|||||
2 km |
5km |
10 km |
20 km |
|||
Nombre d’unités |
70984 |
23848 |
6974 |
2151 |
620 |
|
Unités de moins 500 habitants |
23312 |
1003 |
56 |
1 |
0 |
|
Superficie |
Moyenne |
784.8 |
2403 |
8309 |
26991 |
93643 |
Ecart-type |
1185.9 |
2046 |
4153 |
8854 |
26123 |
|
Coefficient de variation (%) |
151.1% |
85.1% |
49.9% |
32.8% |
27.8% |
|
Population |
Moyenne |
1946.6 |
5794.3 |
19814 |
64241 |
222877 |
Ecart-type |
3035.0 |
6368 |
17961 |
53086 |
166218 |
|
Coefficient de variation (%) |
155.9% |
109.9% |
90.6% |
82.6% |
74.5% |
|
Ecart-type du rapport enfants/femme |
0.16 |
0.11 |
0.09 |
0.09 |
0.08 |
|
A titre d’exemple, nous avons également calculé l’écart type pour une variable donnée, en l’occurrence le rapport enfants/femme (utilisé pour l’estimation locale de la fécondité) ; la forte baisse de la variabilité de l’indice correspond à la diminution du nombre de valeurs extrêmes dans les villages censitaires, c’est-à-dire pour la plupart des valeurs aberrantes liées à des effectifs trop étroits pour un calcul stable de l’indice. La variance ne s’annule naturellement pas, car la fécondité reste très variable en Inde du sud, mais elle enregistre une baisse rapide dès le premier niveau de regroupement spatial.
Un examen plus précis montre que certaines difficultés sont bien résolues, telles que la forme des clusters dans les zones de limites. On sait qu’une méthode de regroupement classique par carroyage en damier (partition perpendiculaire) provoque précisément de graves dommages sur les zones bordières, créant des zones de taille très inférieure aux cellules perpendiculaires de l’intérieur. Demeurent en revanche quelques « trous » dans l’agrégation d’origine : il s’agit des aires totalement dépourvues de localités, comme c’est le cas dans les zones montagneuses ou de forêt dense. De ce fait, certains clusters dans ces régions seront beaucoup plus grands, sans toutefois acquérir une population bien importante. Il n’y a ici guère de remède, sinon le cas échéant d’exclure a posteriori de l’analyse ou de la représentation les zones inhabitées ou sous-peuplées. Une autre méthode consisterait à découper l’espace en polygones de Thiessen, sans passer par une agrégation préalable. Cette méthode résulterait en un découpage encore plus régulier, ne tenant pas compte du regroupement éventuel des villages, mais elle ne réglerait pas la question des zones inhabitées.
[9] Le rapport enfants/femmes offre un indicateur indirect de la fécondité locale. Il est calculé comme le rapport des enfant de moins de 7 ans aux femmes de 7 ans et +.
[10] Il va sans dire que la distance euclidienne est en outre fortement conditionnée par la densité du réseau de communication et la nature du terrain (forêt, pente, etc.).