4.5.1. Opérationnalisation des mesures
Les différentes dimensions de la vulnérabilité rassemblées se déclinent en 14 indicateurs. Douze seront directement pris en compte dans notre cartographie. Les indicateurs d’appartenance aux groupes minoritaires évoqués plus haut ne sont pas utilisés dans ce calcul synthétique initial.
Tableau 6 : Dimensions et critères de vulnérabilité
# |
variables |
Description |
Source |
Variable |
Critère de vulnérabilité |
1 |
Pluviométrie |
Précipitations annuelles en mm |
Atlas of India |
pluvio |
< 75 mm |
2 |
Irrigation |
% de terres cultivées irriguées |
Census |
irrig |
< 20% |
3 |
Fécondité |
Rapport enfants-femme |
Census |
CWR |
>0.5 |
4 |
Alphabétisation |
% de personnes alphabétisées (7 ans et +) |
Census |
littot |
< 50% |
5 |
Mortalité infanto-juvénile |
Taux de mortalité avant 5 ans (rural) |
à partir d’estimations par district |
q5rt |
>100 p. 1000 |
6 |
Proximité urbaine |
Proximité urbaine |
à partir du Census |
Distville01 |
>5 |
7 |
Infrastructures scolaires |
Indice d’infrastructure scolaire |
à partir du Census |
D_ecole_moy01 |
>2.5 |
8 |
Infrastructures sanitaires |
Indice d’infrastructure sanitaire |
à partir du Census |
Distsoinsequal01 |
>7 |
9 |
Accès à la route |
Accès à la route |
à partir du Census |
D_acces01 |
>1 |
10 |
Téléphone |
% de villages dotés du téléphone |
à partir du Census |
ph_fac |
<50% |
11 |
Secteur agricole |
Secteur agricole en % de la main d’œuvre |
Census |
wagric |
>66% |
12 |
Dalit |
% de Dalits dans la population totale |
Census |
dalit |
>20% |
13 |
Tribus |
% de Tribus dans la population totale |
Census |
tribes |
>20% |
14 |
Discrimination de genre |
Sex ratio des garçons pour 100 filles 0-6 ans |
Census |
sr06 |
>110 (f/g) |
Le tableau qui précède fournit une définition rapide des indicateurs individuels, de leurs mode et unité de calcul. On fournit une définition rapide de leur mode et de leur unité de calcul, ainsi que de leurs sources. On notera qu’ils s’expriment de manière très différente : pourcentages, mesures directes, indices factoriels, etc. Dans la colonne de droite du tableau, nous avons indiqué un seuil de vulnérabilité pour chaque variable, qui sera utilisé dans la mesure synthétique. Certains de ces critères proviennent directement de mesures communément admises (aridité, distance, alphabétisation, etc.), alors que d’autres ont été déterminés après examen de la distribution des variables en Inde du sud. Comme on l’indique plus bas, ces niveaux peuvent être recalculés selon un autre jeu d’hypothèses.
4.5.2. Synthétiser les dimensions de la vulnérabilité
Les différentes mesures de vulnérabilité doivent être à présent combinées pour présenter un indice récapitulatif des situations locales. L’objectif est en effet de fournir ici un premier indicateur unique, même s’il est possible dans un second temps de procéder à un examen désagrégé de tous les facteurs individuels.
Plusieurs stratégies existent pour le calcul de cet indice synthétique, mais nous décrirons en premier lieu la méthode retenue ici en raison de sa simplicité. Pour chaque dimension de la vulnérabilité, nous avons déterminé un seuil de risque au delà duquel la localité est considérée comme vulnérable (voir le tableau précédent). On a par conséquent transformé un indicateur continu en un indicateur dichotomique. Pour donner un exemple, on a retenu un niveau d’alphabétisation inférieur à 50% comme seuil de vulnérabilité ; toutes les localités dont moins de la moitié de la population sait lire et écrire sont identifiées comme vulnérables selon cette dimension. Le seuil fixé (voir section précédente) est obtenu par des considérations extérieures sur les systèmes de production et les caractéristiques socioéconomiques des zones rurales. Ces n différents indicateurs dichotomiques sont ensuite additionnés pour obtenir l’indicateur global, variant de 0 à n. Sur l’espace considéré, on obtient alors une distribution ordonnée, quasi-continue, de l’indicateur synthétique de vulnérabilité (carte présentée et commentée plus loin).
Cette approche présente différents avantages. Elle est relativement simple à mettre en œuvre, car elle ne nécessite par exemple pas de décisions délicates sur la pondération des indicateurs. Elle considère en outre que tous les handicaps capturés par nos indicateurs ont un poids équivalent, hypothèse en apparence discutable, mais qui conduit à une approche cumulative : chaque handicap joue un rôle indépendant des autres, se rajoutant à la somme des handicaps sans corriger l’effet d’une autre dimension de vulnérabilité. D’un point de vue statistique, elle débouche sur une distribution quasi-continue, alors que le système de pondération peut déboucher sur des répartitions plus accidentées. Toutefois, cette approche repose directement sur le mode de fixation des seuils, à la manière de la mesure traditionnelle de la pauvreté, et doit par conséquent s’appuyer sur une réflexion fine des niveaux à retenir pour chaque indicateur.
Notons que des approches statistiquement plus sophistiquées consistent à faire varier à la fois la pondération et la valeur des indicateurs. Ainsi, on peut regrouper les indices relevant du même domaine afin de mieux pondérer l’ensemble. On considérera par exemple différents domaines suivants :
- Milieu et développement agricole
- Démographie
- Instruction
- Accessibilité
- Infrastructure
- Diversification économique
- Discrimination de genre
Chaque domaine comprend entre un et trois indicateurs distincts. On dispose ainsi de trois mesures apparentées à l’accessibilité : infrastructure téléphonique, proximité urbaine et accès routier. Une moyenne de ces trois mesures peut être calculée, afin de donner un poids unitaire au domaine « accessibilité » comparable à celui des six autres domaines, décrits eux-mêmes par un nombre variables d’indicateurs. L’indicateur final prendra donc des valeurs plus réduites, allant de 0 à 7, mais avec des valeurs décimales plus dispersées (effet du calcul de moyenne).
La valeur attribuée à chaque indicateur peut également être mieux calculée. Au lieu de s’en tenir à un indicateur dichotomique, on peut partir de l’indicateur d’origine et le standardiser, afin de prendre en compte l’intensité de la vulnérabilité, qui a été entièrement négligée dans le calcul dichotomique. On distingue ainsi les localités par degré de vulnérabilité. Cette standardisation pose toutefois de nouveaux problèmes. En premier lieu, le mode de standardisation à des fins comparatives dépend de la distribution de chaque variable, et notamment de la présence de valeurs extrêmes voire atypiques qui pourraient faire basculer l’indice standardisé. Ceci nécessite donc une étude statistique préalable pour chaque variable et des corrections ad hoc. Une méthode automatique de correction par la moyenne et l’écart type ne semble donc pas indiquée. Ajoutons en plus que la moyenne de chaque indice ne désigne pas nécessairement le seuil de vulnérabilité, divisant en deux l’échantillon en zones favorables ou défavorables. Il se peut que pour certaines mesures, le niveau moyen en Inde du sud rurale soit globalement favorable (ou défavorable) et que l’écart à la moyenne ou à la médiane ne soit pas la bonne mesure. Cette difficulté réapparaît plus bas dans notre discussion.
En second lieu, on peut se demander si des conditions favorables pour certaines dimensions doivent compenser les handicaps découlant d’autres dimensions : une forte alphabétisation dans une localité doit-elle compenser l’enclavement ? La combinaison d’indices standardisés tend précisément à créer ces phénomènes de « rattrapage » d’un indice par un autre, qui ne sont pas forcément acceptables d’un point de vue théorique. Plus précisément, on peut en outre considérer qu’il existe de fait un seuil au-delà duquel la mesure de la vulnérabilité est sans intérêt. Un cas typique est fourni par le sex-ratio enfantin. A un niveau « normal », situé en dessous de 105-110 garçons par fille, les différences ne présentent aucun intérêt (ou marqueraient au contraire une discrimination vis-à-vis des garçons !). De la même façon, un seuil d’irrigation supérieur fixé par exemple à 50 % des terres détermine des terroirs très avantagés et les différences au dessus de ce niveau vraisemblablement de moindre intérêt pour notre mesure de vulnérabilité.
Ces considérations suggèrent donc que diverses décisions doivent être prises pour la préparation de l’indice synthétique. Pour chaque indicateur d’origine, on doit éventuellement :
- Réduire l’intervalle de variation (ignorant les valeurs au-delà d’un seuil)
- Corriger arithmétiquement l’indicateur (logarithme, centrage sur la moyenne, etc.)
- Fixer une pondération au sein d’un même domaine
Il s’agit donc de calculs beaucoup plus fins qui sont dépendants toutefois d’un jeu particulièrement complexe d’hypothèses sur l’étendue des variations prises en compte, la pondération des écarts à la moyenne et la pondération des différents indicateurs entre eux. Il nous a semblé raisonnable à cette étape de notre travail de reporter le calibrage de notre mesure synthétique par un jeu de pondération et de standardisation à plus tard et de fournir dès à présent un calcul statistiquement robuste.
4.5.3. Résultat de l’estimation des niveaux de vulnérabilité
La première carte présentée dérive de l’application de la formule cumulative décrite plus haut. Les douze indices retenus sont en premier transformés en valeur dichotomique 0/1, puis additionnés pour obtenir l’indice synthétique. Les valeurs étalées théoriquement entre 0 et 12 sont en réalité plus resserrées en Inde du sud comme le montre la Figure 31.
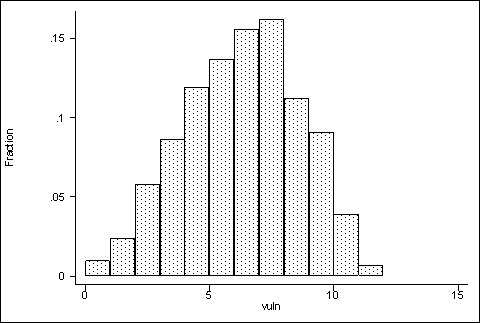 |
Figure 31 : répartition par niveau de vulnérabilité (clusters 2 km)
La première carte obtenue (Figure 32) résulte donc la composition algébrique de différentes cartes « raster » par simple addition des valeurs de chaque couche. Elle fait apparaître une structuration spatiale globale, orientée notamment vers le centre du Deccan qui apparaît comme la région la plus défavorisée. Une poche relativement compacte s’étend le long de la frontière entre Karnataka et Andhra Pradesh. Des poches plus éparses de forte vulnérabilité apparaissent dans des régions tribales, à commencer par la bordure au Nord-Est des Etats du Chhattisgarh et de l’Orissa. Cette situation résulte de la combinaison de plusieurs facteurs régionaux à caractère très divers. En premier lieu, il s’agit des terroirs les plus arides d’Inde du sud et de ce fait, les moins prospères. L’absence de fleuves ou de dispositif d’irrigation, à l’exception des retenues sur la haute Tambraparni, prive les villages du centre du Deccan d’irrigation efficace et les retenues naturelles (tanks) ne collectent pas assez d’eau pluviale. C’est la région marquée par les effets les plus dramatiques des défaillances de la mousson. Mais le développement social de la région est également à la traîne, avec des taux d’alphabétisation parmi les plus bas du pays et des niveaux de fécondité au contraire plus élevés que partout ailleurs en Inde du sud. La mortalité infanto-juvénile y est également très médiocre comme le montrent les cartes de l’annexe II. Le tissu urbain est très épars dans le Deccan et entre les grandes métropoles que sont Bangalore au sud-ouest et Hyderabad à l’est (enclave bleue sur notre carte), la région ne possède aucune grande ville. Ces caractéristiques se combinent donc pour donner à notre indice synthétique une valeur souvent supérieure à 9, largement au dessus de la moyenne de la région.
Les autres régions les plus vulnérables d’après notre indice sont les plus isolées et il n’est guère étonnant de constater qu’elles correspondent en général à des paysages boisés à forte densité tribale, même si ces deux caractéristiques ne rentraient pas dans la construction de notre indicateur. Leur situation interstitielle (entre l’Andhra Pradesh et l’Orissa, ou encore entre le Tamil Nadu et le Karnataka) découle avant tout de leur relief et couvert forestier inhospitalier qui en ont les frontières de peuplement depuis des siècles, ménageant ainsi un sanctuaire pour les populations tribales face à la pression des sociétés des plaines.
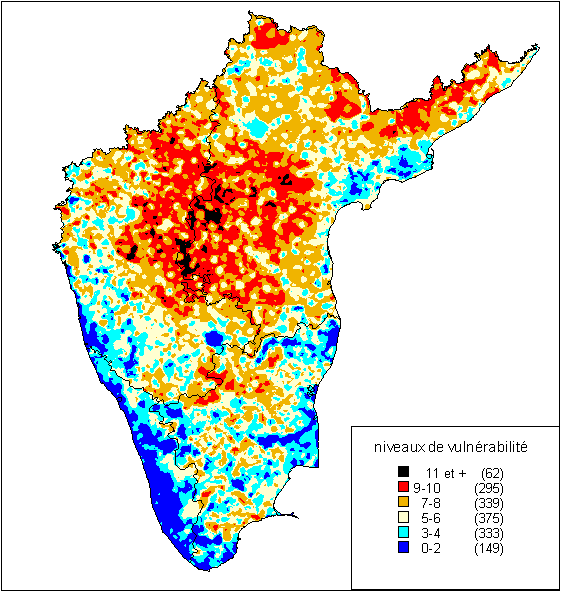 |
Figure 32 : Carte des niveaux de vulnérabilité rurale
A l’inverse, on notera la position relativement périphérique des régions les plus avantagée, qui appartiennent pour l’essentiel au pourtour littoral de la péninsule sud-indienne. On relève notamment l’ensemble du littoral occidental du Konkan, s’étendant de Goa (qui ne figure dans notre ensemble sud-indien) au nord à la pointe méridionale vers l’extrémité sud qui marque la frontière entre Kérala et Tamil Nadu. Les valeurs estimées au Kérala sont particulièrement élevées, mais tendent à s’infléchir le long des Ghâts quand l’on remonte vers le nord-ouest. Le lien négatif entre notre indicateur et le développement social (degré d’instruction, comportements démographiques) est particulièrement manifeste sur la côté occidentale.
Le reste du littoral favorisé fait face à la Baie du Bengale, mais il constitue plus une succession de poches distinctes qu’un ensemble homogène. On y lit les effets de l’urbanisation (comme autour de Chennai) ou la présence de zones deltaïques à très forte productivité agricole (embouchures de la Kaveri, de la Krishna et de la Godavari). Quelques régions urbaines intérieures comme autour de Bangalore ou de Coimbatore déterminent également des zones « rurales » (mais en fait assez urbanisées et industrialisées) privilégiées qui se détachent en bleu sur notre carte.
On notera également que le niveau de variations micro-régionales reste accentué à échelle réduite, en dépit de la présence des grandes formations régionales que nous venons de décrire. A une échelle plus fine, les variations restent en effet prononcées. Certains éléments de notre indicateur de vulnérabilité sont en effet très variables à micro-échelle et c’est par exemple le cas des proximités urbaines (ou routières) et des éléments de développement économique qu’elles induisent via par exemple les activités du secteur non agricole. Ces variations donnent à notre carte cet aspect tacheté et expliquent la présence de petite oasis de développement, souvent périurbaines, dans des régions par ailleurs défavorisées.
Figure 33 : Carte de vulnérabilité rurale au nord du Tamil Nadu
C’est sans doute un des avantages du mode de construction de notre indice synthétique que d’être capable de restituer le « grain » des variations micro de pauvreté. A la différence de l’indice factorielle présenté plus haut, qui tend à lisser les variations locales, l’addition de facteurs distincts conserve à chaque dimension de la vulnérabilité son rôle dans l’indice final. La qualité de la carte permet de surcroît, en des régions données, de se risquer à des analyses géographiquement plus fines et de tester ainsi la vraisemblance de cet indice global.
Ainsi, dans la moitié nord du Tamil Nadu[33] représentée sur la Figure 32, la trace de la Vallée de la Palar qui s’étend vers l’est de Chennai est très visible : elle oppose les villes industrielles situées le long du fleuve aux zones périphériques beaucoup moins prospères, telle que les monts Javadi au sud-est (Oliveau 1998). On distingue aussi plus au sud de cette région la vallée de la Kaveri, le long de laquelle le développement agricole est favorisé par l’irrigation fluviale et dont l’infrastructure urbaine est plus dense qu’ailleurs.
Ailleurs, les terres sont souvent moins fertiles et l’irrigation plus rare et les pôles de développement m’émergent que dans les environs de certaines villes (comme Salem ou Tirupur au sud-ouest) dont l’essor a facilité le développement industriel local avec de nombreuses répercussions sur le développement villageois. On notera en revanche que la trace de la discrimination féminine, particulièrement accentué aux alentours de Salem en raison des pratiques anciennes d’infanticide féminin, a disparu de la carte présentée ici, car la discrimination représente une dimension singulière dans l’indice synthétique, irréductibles aux autres composantes de la mesure de la vulnérabilité.
4.6. Epilogue
Le dernier exemple commenté tend à confirmer la qualité de l’indicateur synthétique que nous avons utilisé. Les résultats semblent en cohérence avec une connaissance plus fine du terrain. Ils permettent en outre de dépasser les mesures intuitives dérivées d’une connaissance qui serait avant tout locale tout en échappant aux généralisations des statistiques agrégées à des échelles supérieures. Il s’agit sans nul doute un instrument d’évaluation plus fiable et transposable de région à région. Mais il ne s’agit ici sans doute qu’une première exploration et les derniers paragraphes se doivent de rappeler les limites de notre exercice.
Le domaine concerné (celui du poverty mapping) est encore peu exploré en Inde. Les travaux disponibles pour les exercices d’identification des zones vulnérables reposent au mieux sur l’échelle des districts, voire des états, et n’aboutissent qu’à des indicateurs plutôt frustres, par rapport des variations micro-régionales des inégalités que nous voulions saisir. En outre, les indicateurs proprement économiques de la pauvreté, mesurée par exemple à partir du revenu moyen des ménages ou de leurs biens, qui complètent d’ordinaire la mesure statistique dérivée d’un recensement sont rarement disponibles à une échelle inférieure à celle de l’Etat ; cela empêche la validation des indicateurs indirects que nous utilisons ici. Il a été question à de nombreuses reprises de l’insuffisance de notre base statistique. Le problème est récurrent et l’intégration de données environnementales et sociales est encore très rare (voir toutefois O’Brien et al. 2004). Le problème complémentaire est la difficulté de joindre analyse globale et données de terrain par ménage, comme cela est courant dans le domaine, ou d’évaluer la perte de qualité des données due à l’utilisation de données agrégées quand elles proviennent du recensement (Minot and Baulch, 2005)
Ajoutons qu’en l’absence d’étude comparable dans le pays, il est difficile d’interpréter de manière finale les variations d’indice et notre travail nécessite une confrontation avec des mesures dérivées d’autres régions. On sait qu’en Inde, la partie méridionale est loin d’être la moins favorisée et il sera donc important de disposer dans le futur d’étalon de comparaison pour d’autres régions rurales. Mais l’expérience du poverty mapping à échelle désagrégée montre que la diversité entre localités rurales en matière de vulnérabilité reste très forte à l’intérieur des unités administratives régionales et que les estimations par village donnent des tableaux beaucoup plus contrastés que les moyennes globales, ce qui a été mis en évidence en d’autres pays en développement quand les données le permettent[34]. C’est précisément l’essor économique régional, avec ces fortes polarités urbaines et ses concentrations géographiques (zones littorale, districts industriels, etc.) qui risquent d’accentuer les écarts de revenu entre groupes sociaux et localités ainsi que la fragilité des économies rurales.
L’effort d’EMIS butte donc ici contre le manque de données comparatives et l’examen des cartes de pauvreté illustre cette situation propre à la géostatistique ou à l’analyse spatiale quand elle s’applique à des pays en développement. En dépit des enjeux que les mesures peuvent revêtir, et le cas des indicateurs désagrégés de pauvreté l’illustre clairement, les pays en développement ne disposent pas encore de savoir-faire ou de données ad hoc pour ce type d’analyse spatiale. Il y a certes un grand nombre de raisons à cette situation, mais la progression des SIG et de la maîtrise de l’information spatiale assure que dans quelques années, ces mesures locales seront disponibles et permettront, au-delà des intérêts avant tout scientifiques que représente notre travail, de se former une image plus claire des paysages de la pauvreté en Inde et de mettre en évidence en particulier les clusters qu’on distingue dans plusieurs régions rurales. Il appartiendra alors à l’ensemble des experts concernés, des géographes aux socio-économistes, de se saisir de ces outils pour interpréter finement ces variations régionales et en tirer les conclusions pour la lutte contre la précarité et la vulnérabilité. Il faut donc espérer que les travaux pionniers comme ceux de notre équipe serviront des points de repère pour les efforts à mobiliser dans les années à venir.
[33] Région familière à plusieurs membres de l’équipe qui ont conduit des travaux de terrain dans diverses localités de cette région.
[34] Pour une illustration à partir de l’exemple indonésien, voir le travail de Sumarto (2003).